Diving into Data Science Part 1
Intro
Some time ago I had decided that I wanted to learn more about data science. I didn’t have a particular sub-topic of data science that I wanted to delve into so I settled upon undergoing a personal project that involved (or had the potential to involve) many different areas.
What Data
To give you some background, I’m a drummer in a band and we recently began the quest for new members. Now something that peeked my interest whilst I was hunting through band advertisements was, what are the statistics of band advertising? Or more specifically I wanted to be able to answer questions like: which city has the greatest number of adverts in relation to its population or what’s the most popular music genre being advertised?
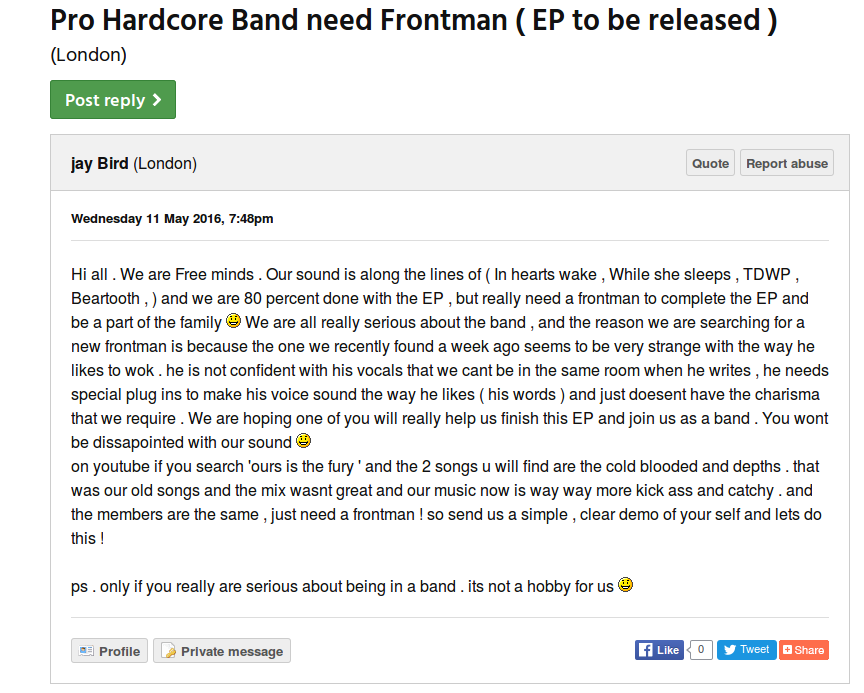
Where I got the data from was an easy choice. Pretty much of all my experience of searching for musicians is from one site called Join My Band. Its a good choice since no login is required to access all the posts and they are already categorised into region. An example ad is shown in the screenshot below:
How to Get the Data
Looking back on it, it probably would be have been easier just to ask the site owner for a copy of the data. But I wouldn’t have learnt as much so I guess it worked out just as well.
I knew that there is technique used to obtain data from a web site called Web Scraping, but I didn’t know anything about it. So I decided to read a book. I had recently learnt the basics of Python so I wanted to do something to cement my knowledge. I found a book on Safari Book Online called Web Scraping with Python which seemed to fit quiet nicely with what I wanted to do. The book lead to me to learn about Scrapy, which is a Python framework for performing web scraping.
With a web scraping tool found I sought out how to store this advertisement data in order to manipulate it later. I had plenty of options on how, but I decided to use MongoDB as I found that saving a python dictionary to MongoDB is really simple and since I didn’t know much about MongoDB it was a good opportunity to learn. Though at the time of writing, Scrapy did not have built in functionality to export the scraped data to a MongoDB database, but I discovered you can add your own item pipeline. Using the Scrapy doc and this helpful blog post I was able to save the data of each band advertisement into a MongoDB database. For each advertisement I was able to scrape:
- Region of ad
- User entered location, often a city
- Text of ad
- The username who posted the ad
- Time and date of when the ad was posted
- Title of the ad
Run Scrapy and Wait.
With Scrapy all setup, I set it off running. Luckily the site displays how many ads are currently in each region so I could roughly work out how long it would take to scrape them. It was configured to request a new ad every 3 seconds which meant it took me about 2 weeks on a single machine to gather close to 300,000 ads.
What’s Next
Now that I have the raw data, part 2 of my project will involve summarising the data to produce statistics like a time plot of ads posted per month.